
I Built an Internal Feedback Loop with Vibe Coding
6/14/2026 · 3 min read
I vibe-coded an internal feedback tool
It started with a stupid morning ritual
I am a PM on a return-to-China accelerator. For a while, my first task every day was not reviewing metrics or setting priorities—it was opening the ticket backend and copying overnight feedback into group chat, one row at a time, then @ ops.
User ID, platform, region, verbatim text, whether logs existed. Not hard. Absurd. No judgment, just labor. Posting did not mean the issue was caught: someone might reply looking into it, but which step they reached, whether to escalate, what the conclusion was—often unknown. The same user could complain several times in a week; in the list those were separate rows I might forget.
The questions I actually need to answer
Users say they cannot connect, acceleration feels useless, streams stay locked, or they want a refund. Support sees the complaints. Ops sees nodes. Engineering can pull logs. I need different answers:
- Is this a product experience issue?
- How many people, and is it clustered by region, platform, or release?
- Should it enter the engineering backlog?
That picture lived across a helpdesk, a ticket backend, failure telemetry, crash logs, and a team IM group. Asked how acceleration looked this week, I often said seems like more node issues or seems concentrated in one region.
The word I hated most was seems. Users say slow, failed, useless; the cause might be nodes, routing, DNS, app version, or local network. Without stitching those together, you only see dots—not the chain.
Why I shipped rough first instead of a full PRD
The normal path is a PRD, alignment meetings, and a scheduled build. Fine—but this was a messy real chain, not a clean greenfield feature. You only learn where it blocks after something runs.
My approach was plain: vibe-code whichever step was dumbest, most repetitive, and most brain-fill that week. Not a demo for show—a way to push the chain forward one step.
Chain 1: from “did I post?” to “was it caught?”
Pain: remember, chase, copy-paste.
Fix: new feedback auto-posts to the team group with platform, user ID, region, verbatim text, and a detail link; rules decide whom to @.
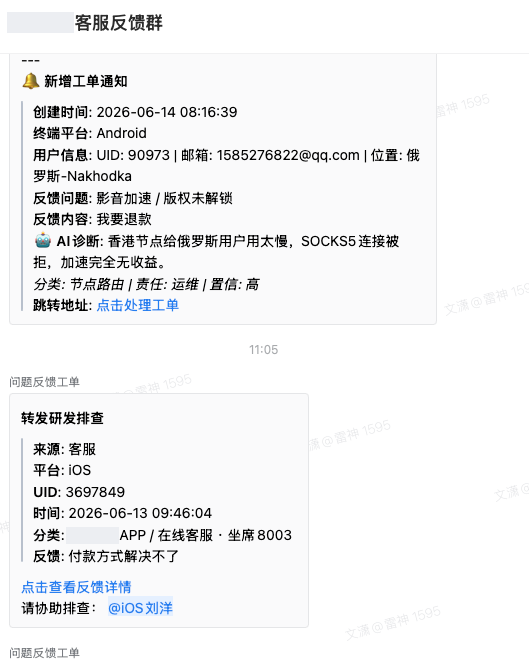
Groups alert; they do not track. I added a board—owner, state, overdue or not, engineering escalation—in one place. The group makes problems visible; the board records whether they were caught.
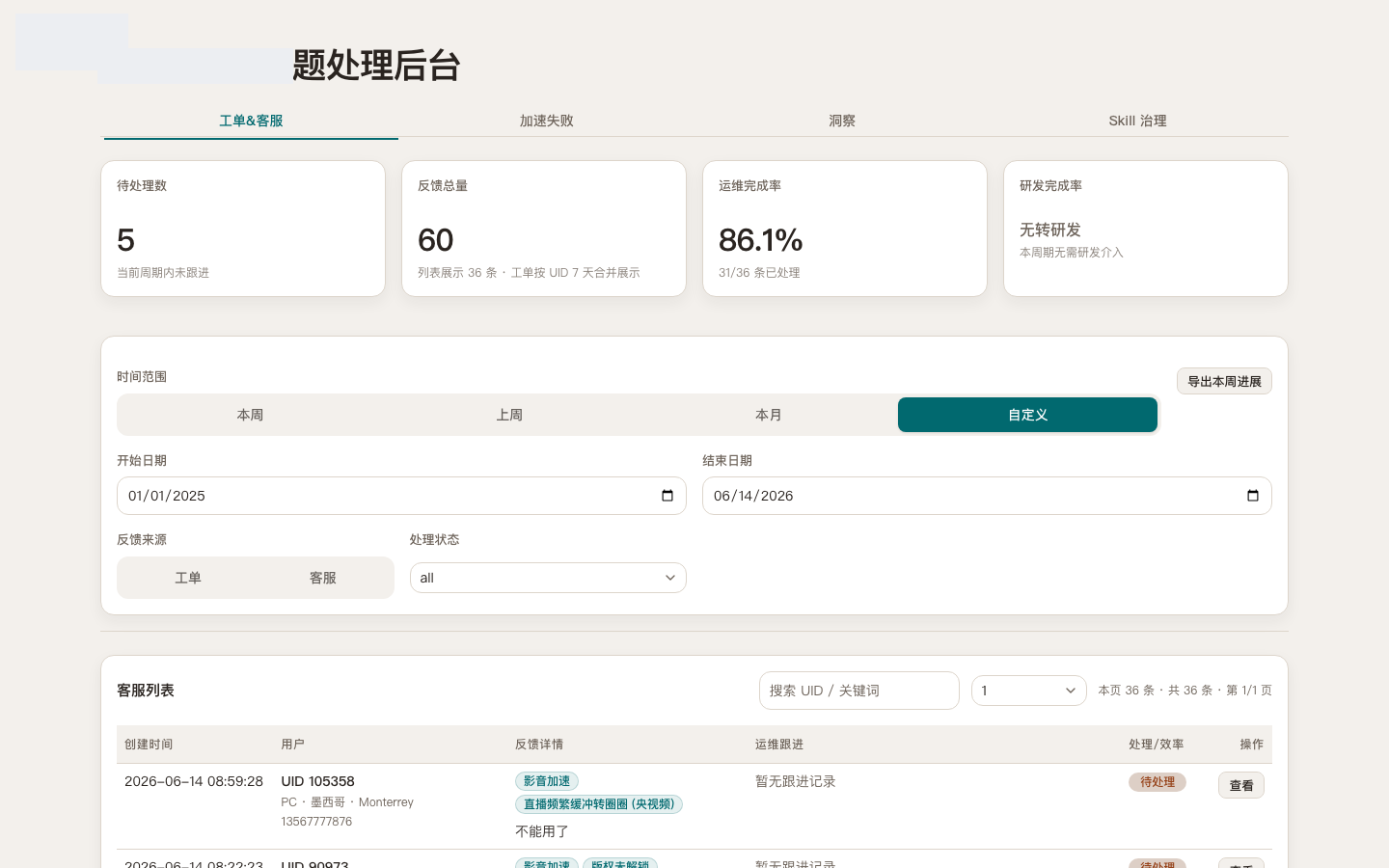
Chain 2: from “cannot connect” to “the log window that matters”
Pain: engineers hunt through huge bundles to find what happened around the complaint. Time goes to search, not judgment.
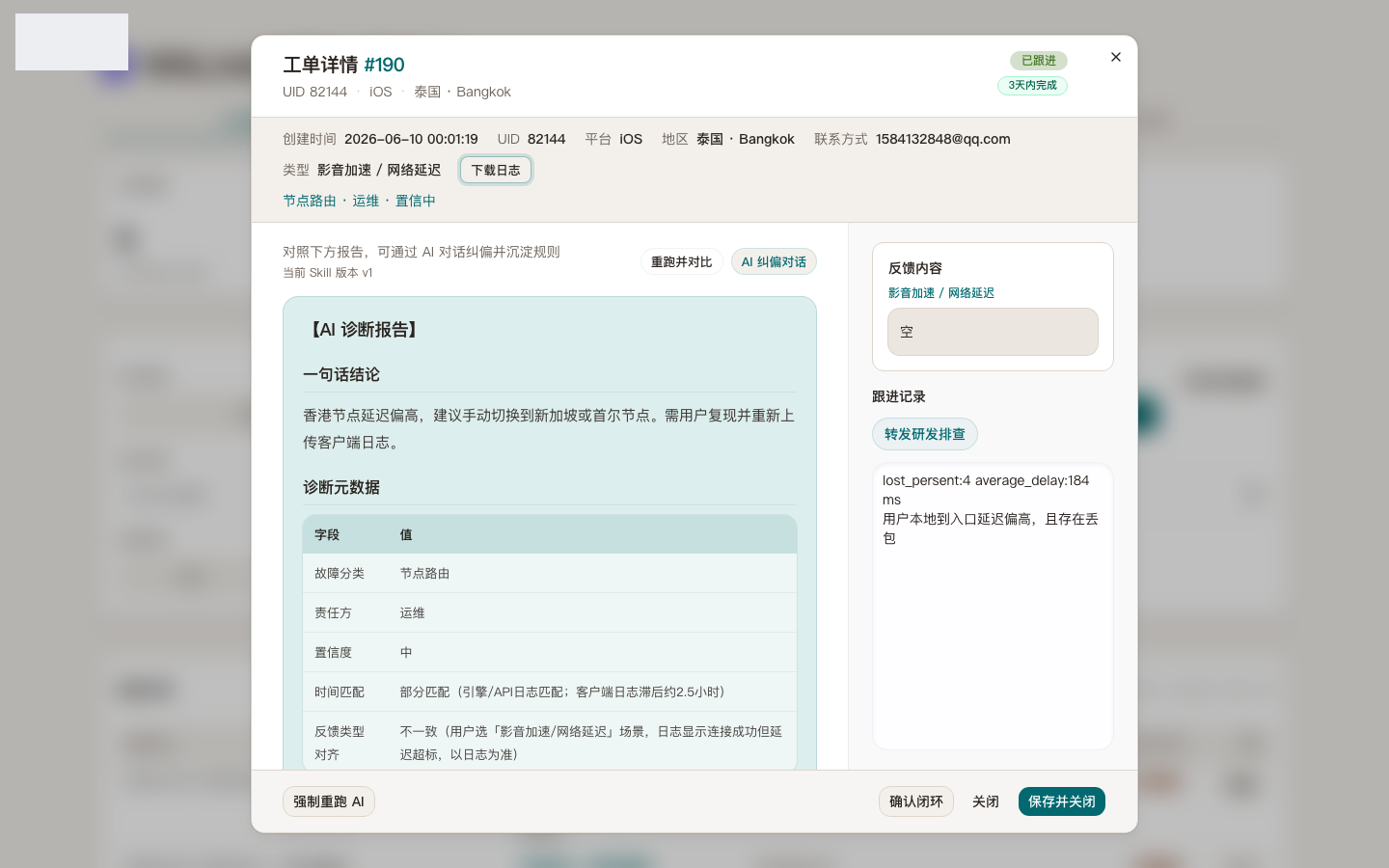
Fix: slice a small log window around the feedback timestamp on the detail page—no verdict, just less repetitive digging.
Assist: a draft from the slice—likely failure type, owning team, suggested checks. No auto-close; humans mark confirmed, disputed, or noise. Less repeat work, not an AI pitch.
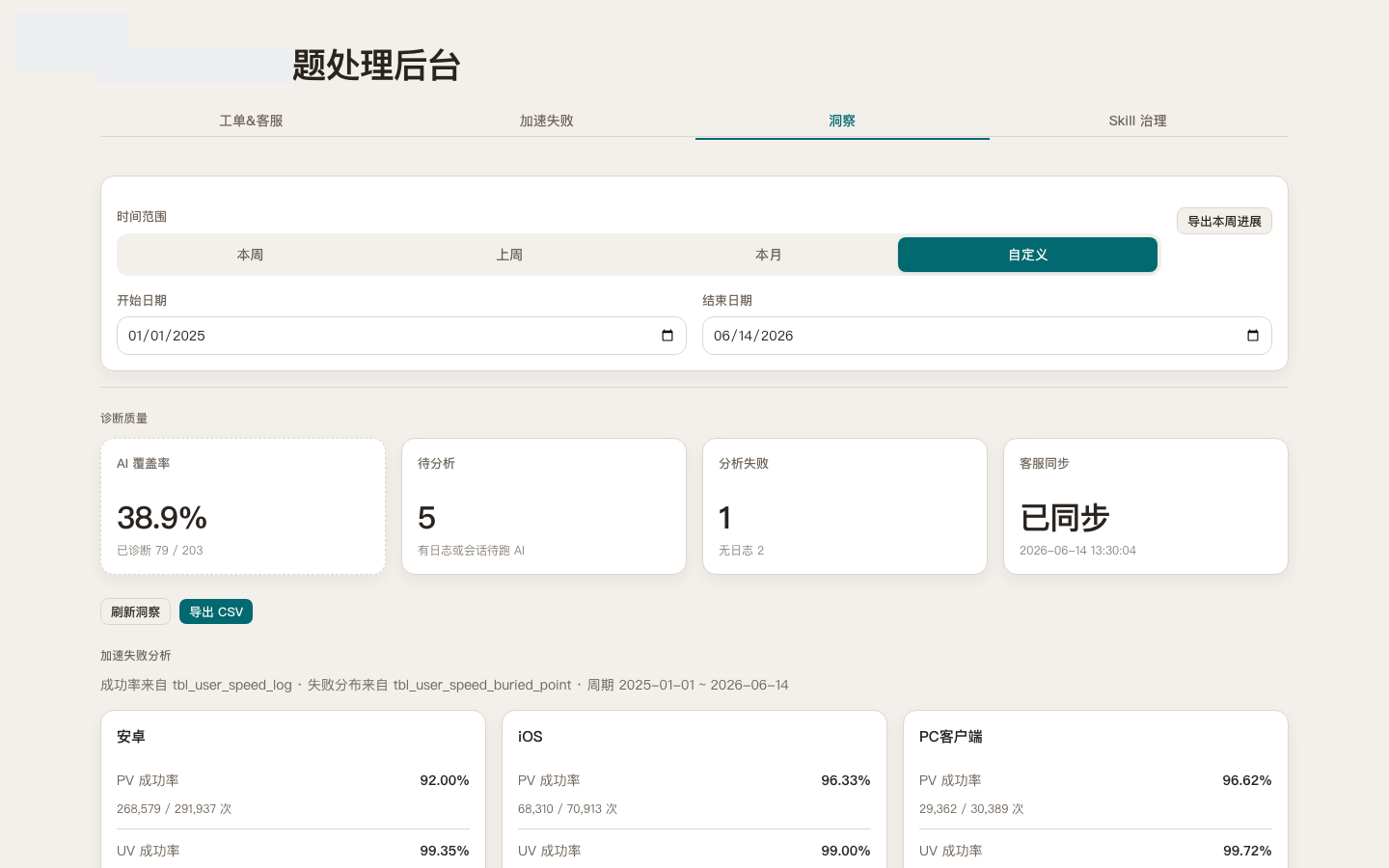
Chain 3: from “one ticket” to “a trend”
Pain: one row shows a case, not whether something is rising this week, where it clusters, or who keeps coming back.
Fix: an insight view plus an acceleration-failure page—success rates and top errors by platform. At least what users complain about and where the system fails sit in one frame.
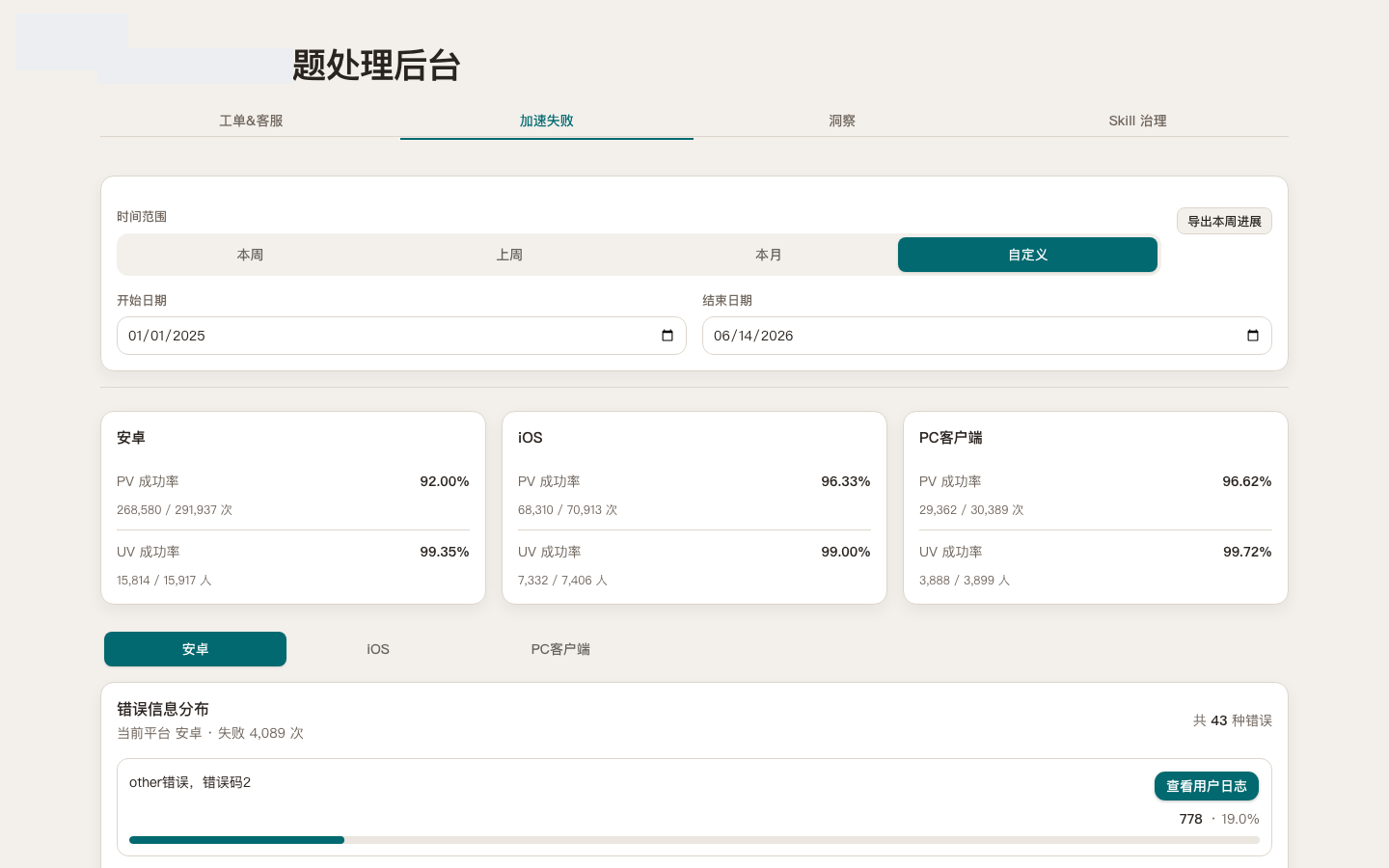
Still open: telemetry and tickets do not auto-link; insight-to-backlog is not fully wired; no uploaded logs means nothing the backend can do; drafts need human review. I did not expect to finish in one pass—unblock the worst steps first.
Closing
Not a Product Hunt launch—an internal tool that grew in the business. Still incomplete.
But I no longer start the day copying tickets into chat. I can put attention back on user experience itself—judging which issues actually hurt acceleration, instead of stitching scattered dots in my head.